How is deep learning influencing marketing? An interview with a Data Scientist

Using deep learning in marketing promises an inspiring junction of science and business. But it’s also very challenging – on one side, there are many questions and theories, but on the other hand, there are few real open market examples and practical explanations. In this article our goal is to dispel doubts, familiarize you with how deep learning is being used in marketing, and inspire CMOs, marketing specialists and business owners to open to these exciting new possibilities.
That’s why I’m talking to Magdalena Wielobób, a Data Scientist at Whites Agency. We will answer the following questions: When can we actually use Deep Learning in marketing and what conditions must be met to do so? What are some market examples? And when is it not actually the best solution?
Specialist: Magdalena Wielobób, Data Scientist, Whites Agency
Interviewer: Martyna Biskupska, Marketing Specialist, Whites Agency
How would you explain in a simple way what Deep Learning is?
Magdalena Wielobób: Most often, people explain that deep learning means processing information via structures inspired by the human mind, but I am a woman with an engineering mentality and I would say it a little differently. In the case of deep learning, we deal with algorithms, and we can define an algorithm as something that has an input – here comes the data, and an output – we will talk about it in a moment – and between the two, we have a planned procedure for solving a problem.
So we have a problem, we have data and we have some answers. If it seems similar to programming, then a little bit yes and a bit no. What are the differences? In programming, we have data and rules that someone has invented and written, and finally, using those rules in the algorithm, we get answers. Now, in machine learning and deep learning we also have data and answers, but we use these tools to get the rules – these are our algorithms, the most important element. Then we can use these rules on data that the algorithm has not seen or learned about. In this way, we get more complete answers, covering a much wider scope than in programming. Deep learning finds nonlinear dependencies that a human cannot capture, and underneath is pure mathematics.
I will also discuss the difference between deep learning and machine learning. Well, honestly, there are more similarities than differences because deep learning is part of machine learning. In deep learning, we have a slightly different set of tools to choose from – we use neural networks that can extract features themselves, and they work especially well on multidimensional data, such as, e.g., images, text, sound or when we have a lot of simple data. Deep learning can work on simple problems better than simpler methods can, but only when we have a lot of data.
Why should we use Deep Learning in marketing in the first place?
MW: Let’s start with the fact that the marketer has to have a problem to solve. We can’t just take data, put it in a box and get a magic solution. We must have something to solve. So let’s talk about what problems can be solved with these methods.
So what problems can marketers solve with deep learning? What are examples of using Deep Learning in marketing?
MW: To answer this question, let’s go back to data types for a moment. As we established earlier, data doesn’t only mean numbers in an Excel table, but also text, images and sound. Let’s take a closer look at various types and their related solutions.
Graphics data and images.
We use deep learning to recognize faces, logos, and emotions. There are also photo processing solutions for e-commerce, i.e., for retouching or sharpening an image, or cutting one object out from the background.
![]()
Source: https://cloud.google.com/vision/docs/detecting-logos
Text, more specifically the recognition and classification of text.
Deep learning is used in the context of natural text machine understanding (NLP – natural language processing). You can really use it in many ways. I will give a few examples.
1. Assisting the assignment of complaints to categories – for example, Uber and many other companies have a lot of client complaints to resolve. A machine can classify them much faster and save time, thus improving service.
2. Analysis of the sentiment of comments on social media, i.e., whether a statement is positive, negative or neutral. This is a more complicated issue, assuming that comments can be, for example, ironic.
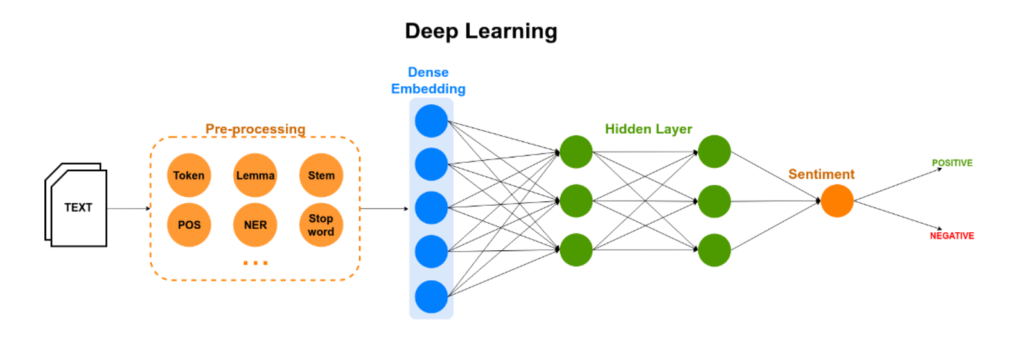
Source: https://www.mdpi.com/2079-9292/9/3/483
3. Chatbots that are implemented to increase customer satisfaction with brand interactions – improving customer service, ensuring that they receive a response very quickly, even at odd hours. That’s why we care about the machine’s understanding of the text.
There are also more mundane, less “romantic” problems, and a large field of deep learning is found in the recommendation systems used in email marketing.
Next, it can be used for advertising optimization and targeting optimization – and here is the most important thing: it happens real-time.
4. Others
Price optimizations. Anticipation of whether demand is increasing or decreasing, or if consumers are stocking up on the given product. These are problems where perhaps humans could do it better, but they would be physically unable to handle this amount of data.
From practical examples: with our Research & Development team at Whites Agency, we hack the Google algorithm to advise companies on advanced SEO. We are also working on the automatic allocation of marketing budgets to get the best return on investment in multi-channel campaigns for the same money.
I’m sure I have omitted something in these examples. It is a versatile tool that can be applied wherever there is data and a problem to be solved.
What do we need in order to use deep learning in marketing?
MW: First, data – a large amount of data. How much qualifies as large? There is no definite answer to this and it all depends on the complexity of the problem. If the problem is more complicated, we need more data and more types of data to cover a wide variety of cases.
Example
If you want to recognize whether an image presents a cat or a dog – this is a classic example – we need an adequate number of diverse images of dogs and cats in various positions. At home and outside. Or, if we want to recognize the type of shoe – we also need to have appropriate photos of different types of shoes, on different backgrounds, colors, etc. But if we don’t simply want to recognize 3 types of shoes, but instead want to recognize what is in the photo in general – e.g., 1000 different things – this is a more complicated problem that will probably require a different solution architecture, but also different kinds of data and much more of this data.
Datasets can be downloaded for free or purchased. Many of these ready-to-use products are intended for strictly scientific use, but there are also certain commercial licenses.
Secondly, we need structures in which to store this data so we can extract it whenever we need it.
Thirdly, we need people. This includes those who deal with data storage, i.e., directing this data somewhere, so that it does not get lost and ensuring data compatibility, the people who work with this data, and those who manage the whole project.
Fourth: computing resources. This also depends on the type of problem and the type of data. More computing resources may be consumed by large amounts of photos than sales data in a medium-sized company. There is no clear answer to the question of how extensive your computing resource needs will be, but you have to take into account that this is a cost and most problems cannot be processed on an ordinary computer, even a good one, but only in the cloud.
And most of all: a problem to solve. If we just start by noting that we have data, because everyone collects data, and then we try to figure out what to do with it, we are going about things all wrong. Such a path rarely brings good results. At the same time, we have to think about defining our problem in terms of implementation. Is it something that will work offline or is it supposed to work online in real-time? Because, each of these cases needs to be approached differently.
As an example of offline and online activities, let’s return to recommendation systems. Let’s say there’s a system that works online when a user goes to a website (the system collects his or her data) – it needs to react very quickly. Just like Google returns results in fractions of a second, not a few seconds. Nobody will wait a few seconds.
Another example of a recommendation system is when you have a customer base on a local computer in your company and you have a model that calculates what to send them in the email – what to recommend to them.
When is deep learning not the best solution for marketers and businesses?
MW: As I mentioned before, you have to have a problem to solve – that is, just uploading data and seeing what comes out is not a good idea. And it has to be a problem that you cannot solve by other means (due to time, costs or simply resources) and for which effectiveness can be measured. Of course, we have a lot of metrics tailored to different problems, but you have to ask yourself which one to choose. There are cases where when someone chooses the wrong metric, they may solve a problem, but not the one they wanted.
|
It is also worth adding that the metric – i.e., some numerical value after measuring the quality of the model’s operation on data that it has not seen before – must be interpreted by a human – one who knows both how the models operate and who knows the problem being solved, i.e., a domain expert.
Further, deep learning is not the best solution for marketers and companies if the company’s future depends on the success of the project. Why? Because whenever we deal with artificial intelligence, it is an element of the Research & Development department, not of IT departments, i.e., it is an element of exploration and testing. When programming, the effect is always predictable. In machine learning and deep learning – we know what effect we want to achieve, but we cannot be 100% sure at the beginning if our data is good and if the problem can be solved. Of course, we collect such information and we know from experience where to use and where not to use these tools.
Another example is when we have little or no data – we know in advance that we are missing something. Or if we have a lot of data but it is of questionable quality. There is a saying among data scientists: “garbage in, garbage out.”
However, I would like to point out that cleansing data and combining different sources is of course part of our job. Data is never perfect and can’t be expected to be. Simply put, if we know in advance that the data is not good, the quality of the data needs to be dealt with first. It is often the case that if this data is insufficient, you just have to collect more; sometimes it will take longer, but it will eventually work.
|
Another situation where deep learning is not recommended is if no analytics has been implemented in the company and we are not able to answer basic questions about business and customers. Finally, one of the most important considerations is when we can gain too little in comparison to the costs incurred. For example, in manufacturing, if you improve production by 0.5% or 1.5%, the savings can be in the billions of dollars. In that case, it is worth the cost, the time spent and the fact that different parts of the company may have to get involved in such a project. But if the return on investment is insufficient, it simply isn’t worth it.
What is the future of DL in marketing in your opinion?
MW: Deep learning and AI may seem complicated. From a scientific point of view, this is somewhat true, but their use makes it easier for people to work on a really large scale. There are already a whole lot of examples of using deep learning, and there are many more to come up with, and to transfer from one area to another. Networks that recommend how to position yourself on the web or how to divy up your marketing budget are not just the domain of the future, but can help you now, in the present.
Especially since we are constantly observing the development of technology and, just as we can buy a better computer for the same price today than we could two years ago, the computing resources needed in deep learning will also get cheaper. As I mentioned before: as long as there are problems to solve and data to rely on, deep learning will be applicable. And many of these are already being solved with this method.
About the specialist

Magdalena Wielobób, Data Scientist at Whites Agency