Introducing Doc2vec algorithm by NLP and its use in SEO

Doc2vec (2014, Mikolov et al.) makes it possible to find constant size representation for documents with varying lengths, which is better than a Bag of Words. How?
What is the Doc2vec algorithm?
The algorithm introduces the paragraph vector, which is unique for each paragraph, unlike word vectors, which are shared for the same words. Word vectors contribute to a prediction task about the next word in the sentence. Similarly, paragraph vectors “are asked” to predict the next word given many contexts sampled from the paragraph.
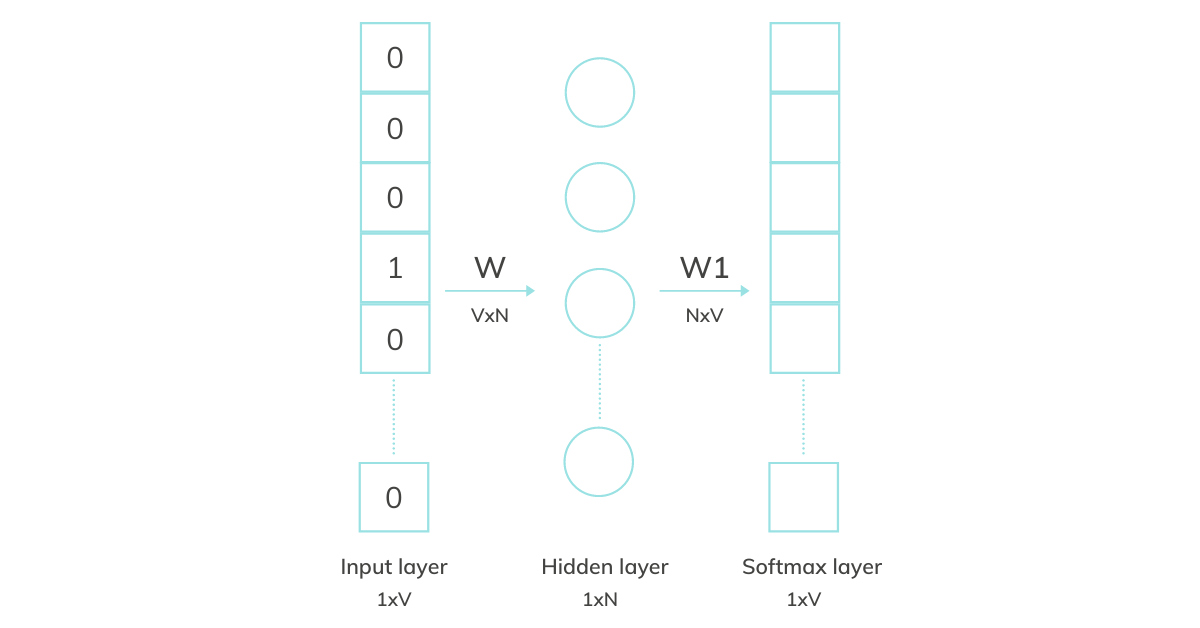
Source: https://shuzhanfan.github.io/2018/08/understanding-word2vec-and-doc2vec/
Every paragraph is mapped to unique vectors, which is represented by a column in matrix D, and every word is mapped to a unique vector which is also represented as a column but in a different matrix, W. Both paragraph and word vectors are combined (either concatenating or averaging) to predict the next word in a context. This embedding is trained similarly as word2vec was; the change here is the presence of paragraph embedding, which represents the missing information from the current context.
Doc2vec in summary has two key stages:
- training to get word vectors, softmax weighs U, b and paragraph vectors D on already seen paragraphs
- “the inference stage” to get paragraph vectors D for new paragraphs by adding more columns to D and gradient descending on D, while holding W, U, and b fixed.
How can you benefit from Doc2vec?
A big advantage of this approach is that it learns from unlabeled data, not to mention that it was shown to strongly overperform so far used models like Bag of Words.
This kind of embedding might serve for unsupervised clustering of related documents using, for example, a k-means algorithm, which would allow classification of texts that are similar to each other.